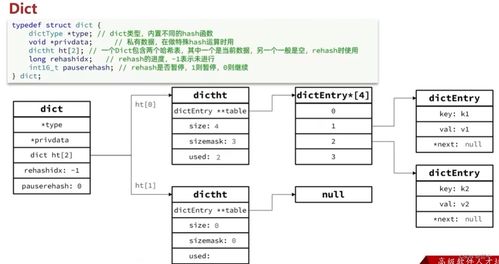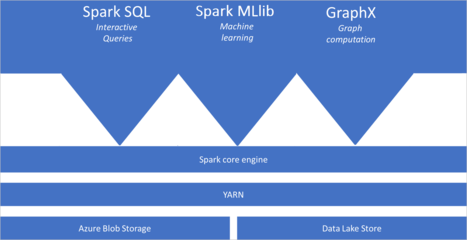
Azure Synapse Analytics 中的 Apache Spark 是一種快速、大規模并行處理的數據分析引擎,它作為 Azure Synapse Analytics 的核心組件,提供了強大的數據處理和存儲支持服務。
Apache Spark 在 Azure Synapse Analytics 中的核心價值體現在多個方面。在數據處理方面,它支持批處理和流處理,能夠處理從 GB 到 PB 級別的海量數據。用戶可以使用 Scala、Python、SQL 和 .NET 等多種編程語言進行數據開發,通過 Notebook 界面進行交互式數據分析。
在存儲支持方面,Azure Synapse Analytics 的 Spark 池與 Azure Data Lake Storage Gen2 深度集成,可以實現統一的數據存儲和訪問。同時,它還支持多種數據格式,包括 Parquet、JSON、CSV 等,并能與 Azure SQL Database、Cosmos DB 等數據服務無縫連接。
Spark 在 Azure Synapse Analytics 中的優勢包括:
- 無服務器 Spark 池,無需管理基礎設施
- 內置連接器支持多種數據源
- 與 Synapse SQL 引擎的深度集成
- 自動優化和性能調優
- 企業級安全性和合規性
通過使用 Azure Synapse Analytics 中的 Apache Spark,企業可以構建端到端的數據分析管道,實現數據湖和數據倉庫的統一管理,大幅提升數據處理效率和數據分析能力。